こんにちは、VRAMラボです。
今回は同じVRAM容量を持つ二つの世代の違うグラフィックボード(GPU)を使用して画像生成の比較を行いました。
前回の記事で重量級モデルでなければVRAM12GBでも最新モデルでの画像生成が可能なことは確認できました。
VRAM容量でできることが決まるのであれば、GPUの性能の違いはどこに現れるのでしょうか。
結論から言うと、GPUの性能の違いは「生成速度」に現れました。
今回はVRAM容量の世代の違う2つのGPUを使用し、同じモデル・同じ設定で実際に画像を生成して生成速度の比較を行います。
測定環境と検証内容
- 検証機:RTX 4070 12GB 及び RTX 3060 12GB(※)
- 検証モデル:Illustrious・Z-Image・Qwen-Imageの3種類
- ComfyUI 0.24.0、生成は1024×1024、各モデルとも同じ設定・シードは毎回変更
- 生成時間はモデル読み込み後の2回目以降(定常)の値を計測
※RTX 3060は定常負荷として約2.7GBを常に使用した状態で計測
測定結果
2つのGPUともにIllustrious・Z-Image・Qwen-Imageの3種類のモデルによる生成に成功しました。
以下の表とグラフは1024×1024で1枚あたり、生成にかかった時間です。
| モデル | RTX 4070 | RTX 3060 | 速度差 |
|---|---|---|---|
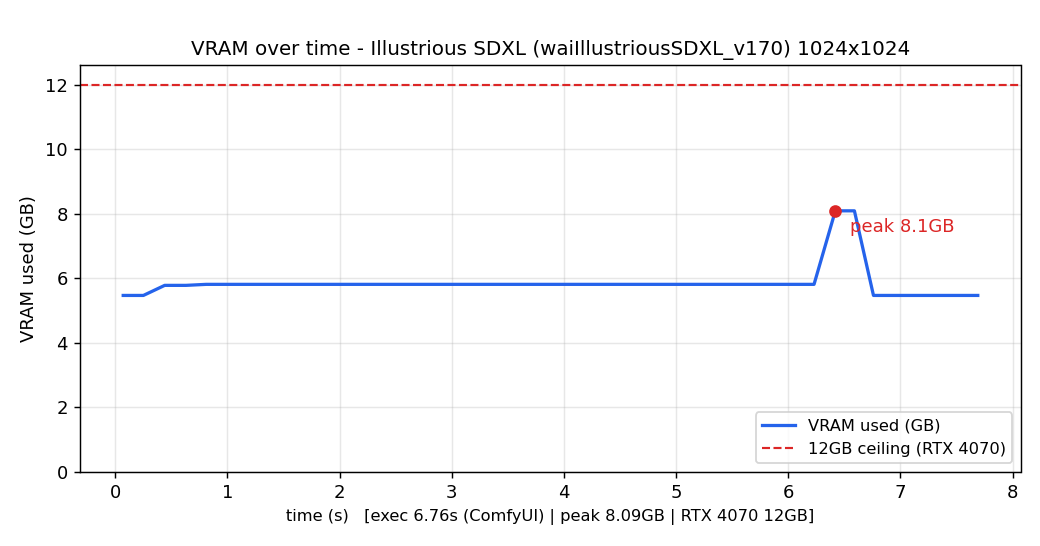
| Illustrious系(軽い) | 7.2秒 | 16.0秒 | 約2.2倍 |
| Z-Image Turbo(ぎりぎり) | 9.5秒 | 23.5秒 | 約2.5倍 |
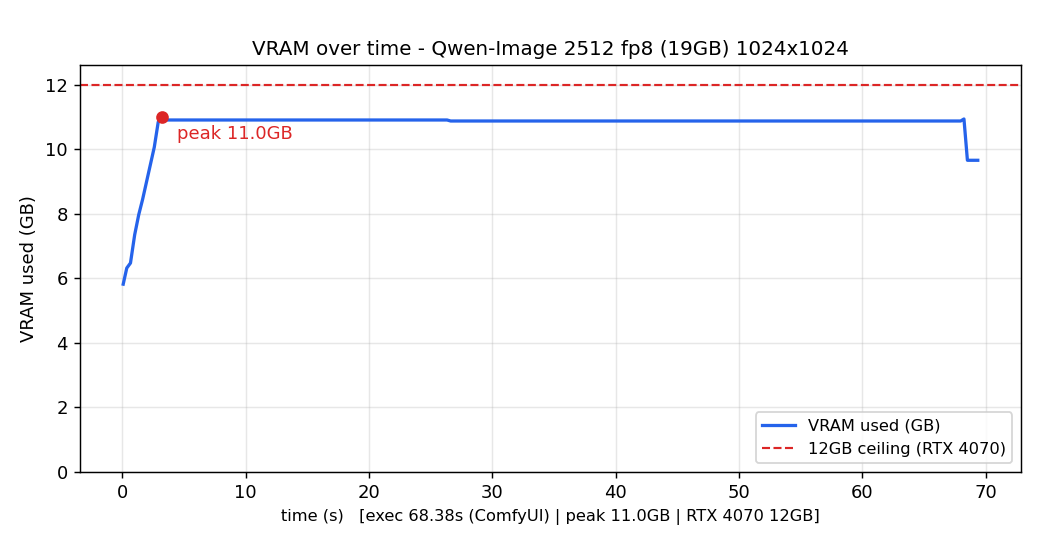
| Qwen-Image(重い) | 76.6秒 | 174.2秒 | 約2.3倍 |
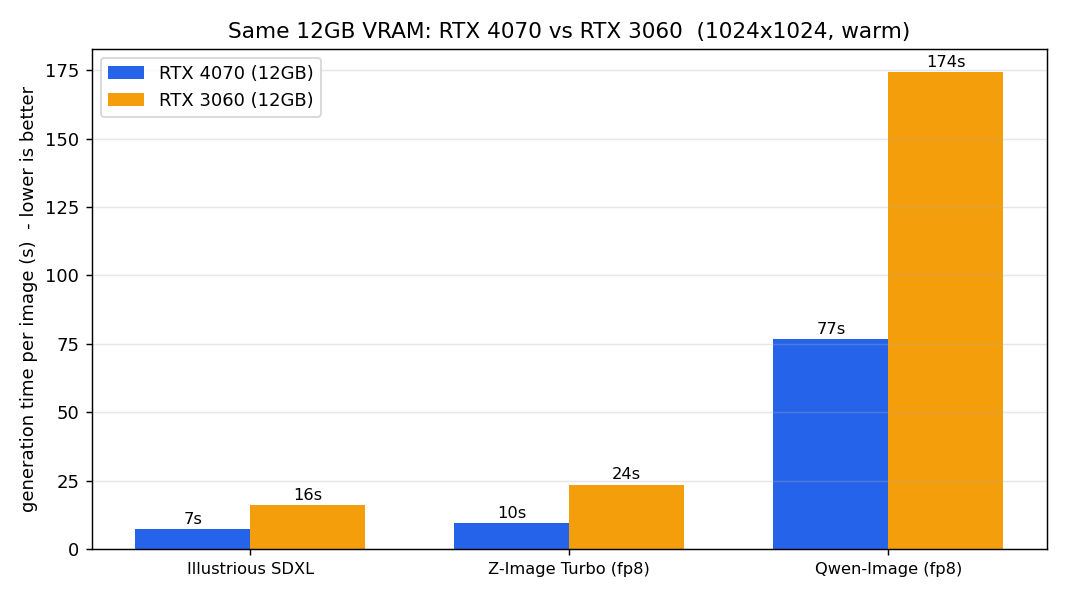
測定結果からRTX 4070のほうがRTX 3060と比べて一貫して約2.2〜2.5倍生成時間を短縮することができることがわかりました。
定常負荷の影響について
最初に提示した測定環境の中で「RTX 3060は定常負荷で約2.7GBを常に使用した状態」と記載しています。
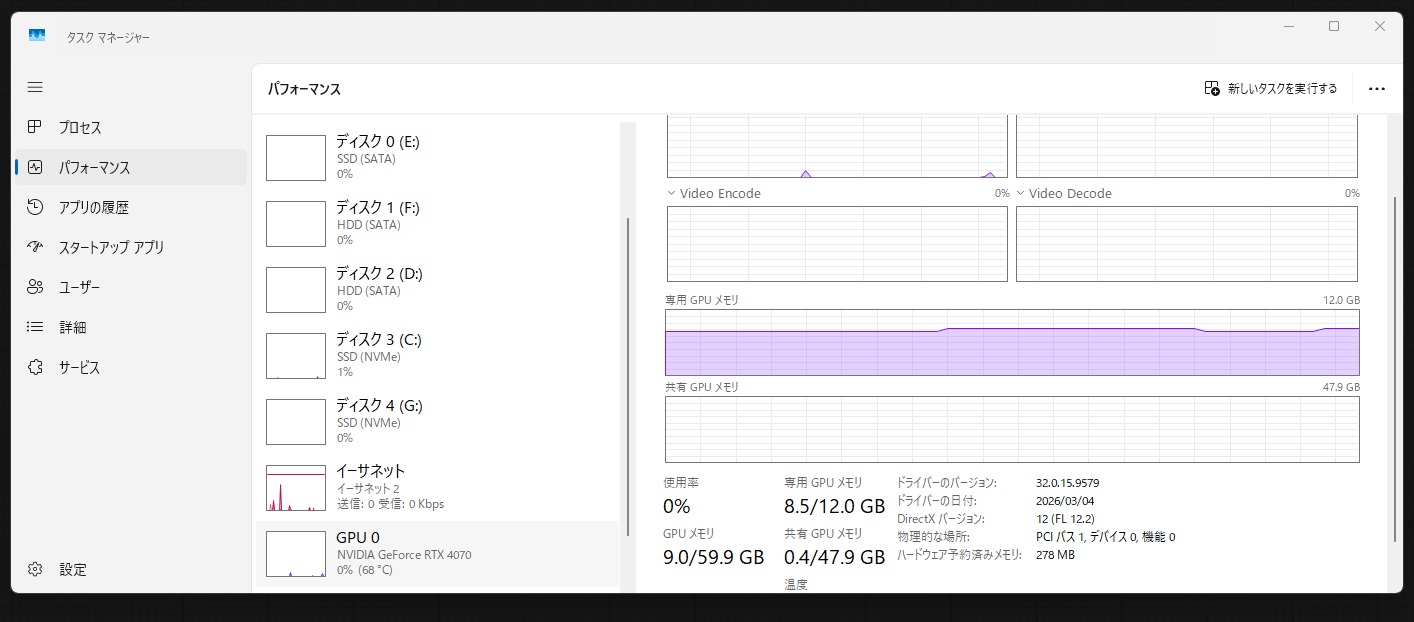
実は生成速度の差には定常負荷の有無が影響しているのでは?と思い生成中のGPUの動きも計測しました。
図はIllustrious画像生成中のGPUの動きをグラフ化したものです。(上:RTX 4070 下:RTX 3060)
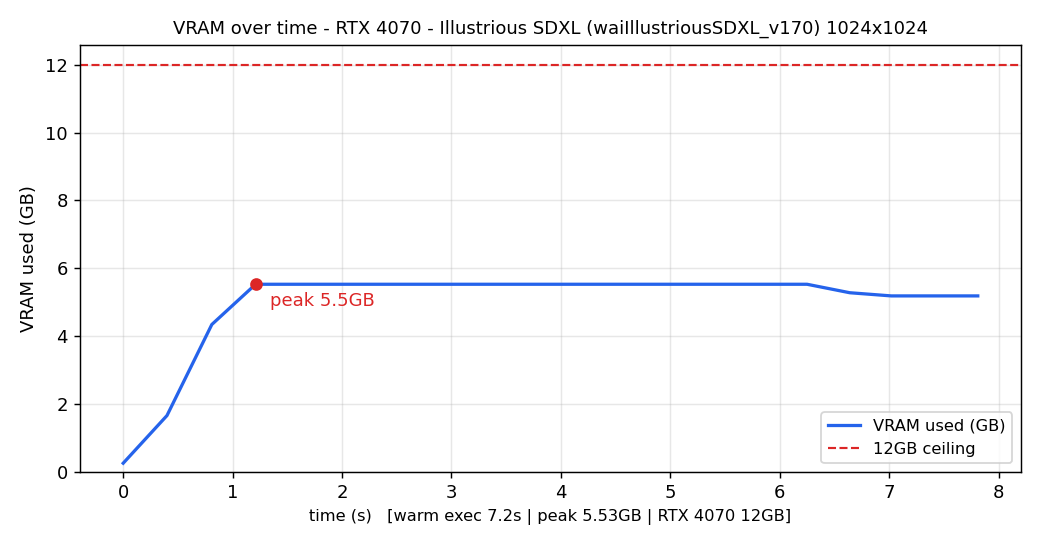
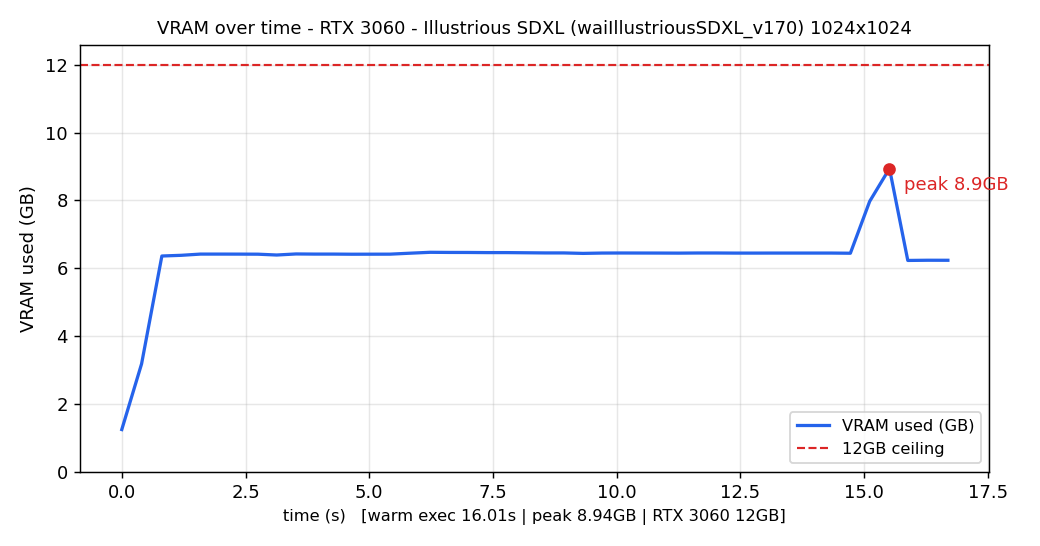
両図を見るとIllustrious生成中の両GPUのピーク使用容量は共に12GB(赤い点線以下)に収まっています。
生成速度の遅延が発生するのは図中の赤い点線を超えた場合のため、定常負荷が生成速度に影響していないことがわかります。
にもかかわらず生成速度に2倍以上の差が出るということは、GPUの世代の差がそのまま生成時間に出ているということになります。
生成画像の品質の差について
次にGPU毎の生成画像の差が出るか確認してみます。




生成画像のseed値が違うため厳密な比較ではありませんが、生成画像の品質には大きな差は見て取れませんでした。
まとめ
VRAM容量が共に12GBの世代の違う2つのGPUを使用して画像生成を行ったところ、
- RTX 4070で生成可能なモデルについてはRTX 3060でも生成が可能
- RTX 4070がRTX 3060に比べて約2.2〜2.5倍速く画像生成が可能
- 生成される画像の品質には大きな差は見受けられない
このような結果となりました。
今回使用した検証機はいずれも現行機よりも世代が古く、RTX 3060に至っては使用モデルによって生成そのものは出来てもあまりにも時間がかかります。
私自身もRTX 3060は画像生成用途として使ったことがなかったため、ここまで差が出るとは少々驚きでした。
画像生成だけではなく動画生成も視野に入れた場合、最新機のVRAM16GBくらいが快適に使用できる最低限になりそうです。
それでは今回はここまで
関連リンク
 RTX 5070(12GB) — 実測機(RTX 4070)の最新機
RTX 5070(12GB) — 実測機(RTX 4070)の最新機 RTX 5060 Ti 16GB — 実測機(RTX 3060)の最新機かつVRAM容量が大きい
RTX 5060 Ti 16GB — 実測機(RTX 3060)の最新機かつVRAM容量が大きい  RTX 5070 Ti(16GB) — 実測機(RTX 4070)の最新機かつVRAM容量が大きい
RTX 5070 Ti(16GB) — 実測機(RTX 4070)の最新機かつVRAM容量が大きい