今話題のアニメ特化モデル「Anima」を、ComfyUIごとゼロから導入してみました。
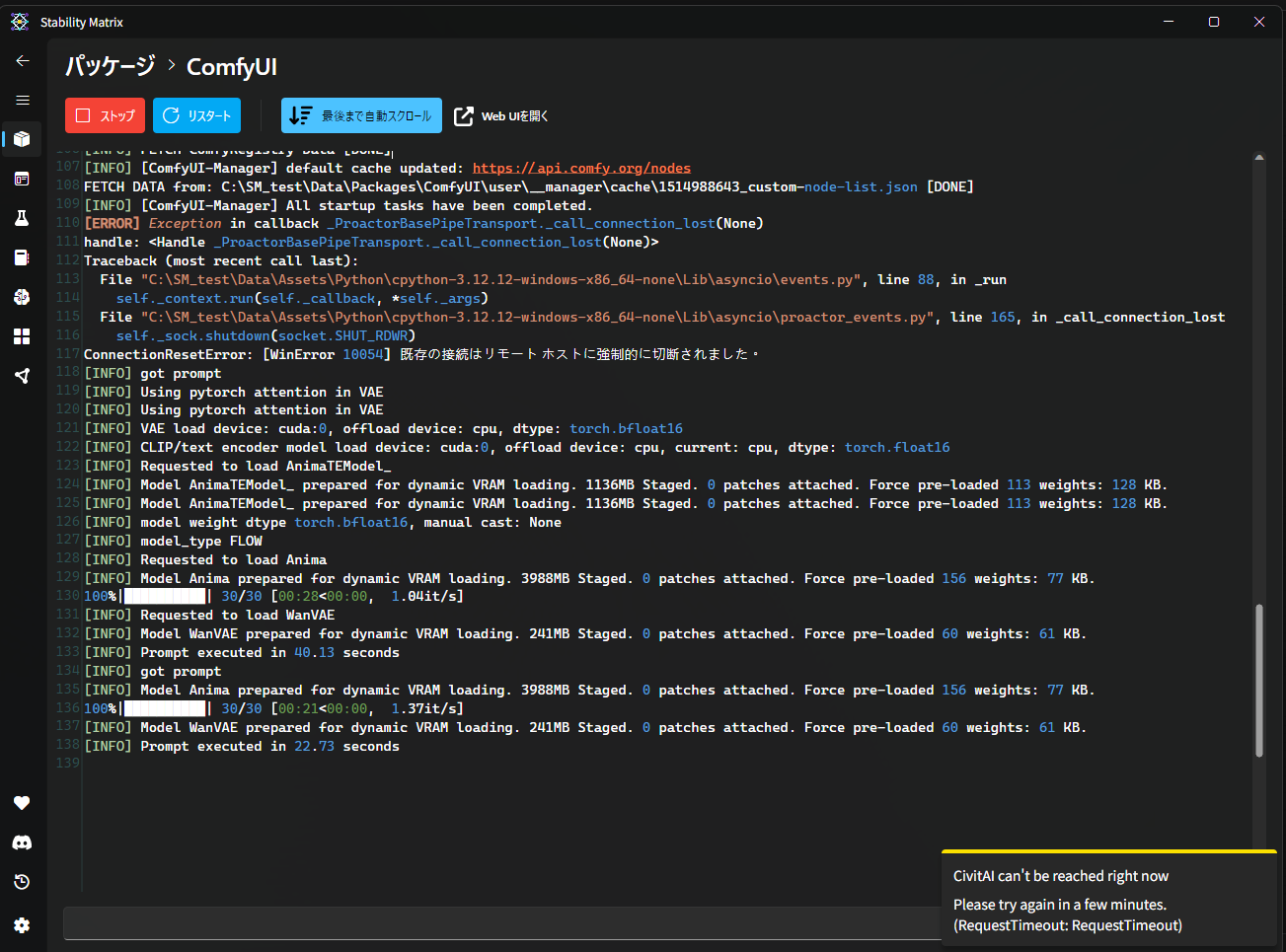
その結果——RTX 4070(12GB)で、1枚約23秒・VRAM 8.5GBで動きました。
必要なのはディスク15GBの空きだけ。この記事の手順と数字は、すべて実機で実測したものです。
この記事でできるようになること
画像生成ツール「ComfyUI」を導入し、アニメ特化モデル「Anima v1.0」で最初の1枚を生成できるようになります。
実測の結果は、
- 初回生成(モデル読み込み込み): 約40秒
- 2回目以降: 約23秒
- VRAM(グラボ内蔵のメモリ)使用量: 8.5GB前後
12GBのグラボに、余裕を持って収まりました。

必要なもの
- NVIDIA製GPU(CUDA対応が必須)
- ディスクの空き容量15GB以上
検証機は、Core i5-14500+RTX 4070(VRAM 12GB)です。
容量の内訳は、
- ComfyUI環境: 8.89GB
- Animaモデル一式: 5.2GB
合計14.26GB(実測)でした。
インストール方式は3つある
ComfyUIの入れ方は、大きく3つあります。
- Desktop版 — 公式推奨。インストーラ一発の単体アプリ
- Portable版 — zipを展開するだけの単体版
- Stability Matrix — 複数の生成UIとモデルを一括管理するランチャー(本記事はこれ)
当サイトがStability Matrixを使う理由は、
- モデルを複数のUIで共有できる
- UIの追加・更新の管理が楽
という実運用上の実感です。
公式推奨でない方式であることは、正直にお伝えします。その上で、筆者が普段から使い続けている方式だからこそ、手順と実測値に責任を持てる——という立場で書いています。
Stability Matrixの導入手順
手順1. GitHub Releasesからダウンロード
公式のリリースページから、最新版(執筆時v2.16.0)の「StabilityMatrix-win-x64.zip」をダウンロードします(134MB)。
手順2. 展開
ダウンロードしたzipを右クリック→「すべて展開」。
展開先は、空き容量に余裕のあるドライブの新しいフォルダ(例: C:\StabilityMatrix)がおすすめです。
手順3. 起動
展開したStabilityMatrix.exeをダブルクリックします。
最初にアナリティクス(匿名の利用状況送信)の同意画面が出ますが、Share / Don’t Shareのどちらを選んでも先に進めます。
手順4. ComfyUIの追加
「+パッケージの追加」からComfyUIを選び、インストールします。
PyTorchなどのダウンロードが走るため、ここはしばらく待ち時間があります。
モデルの配置と「共有フォルダ」の仕組み
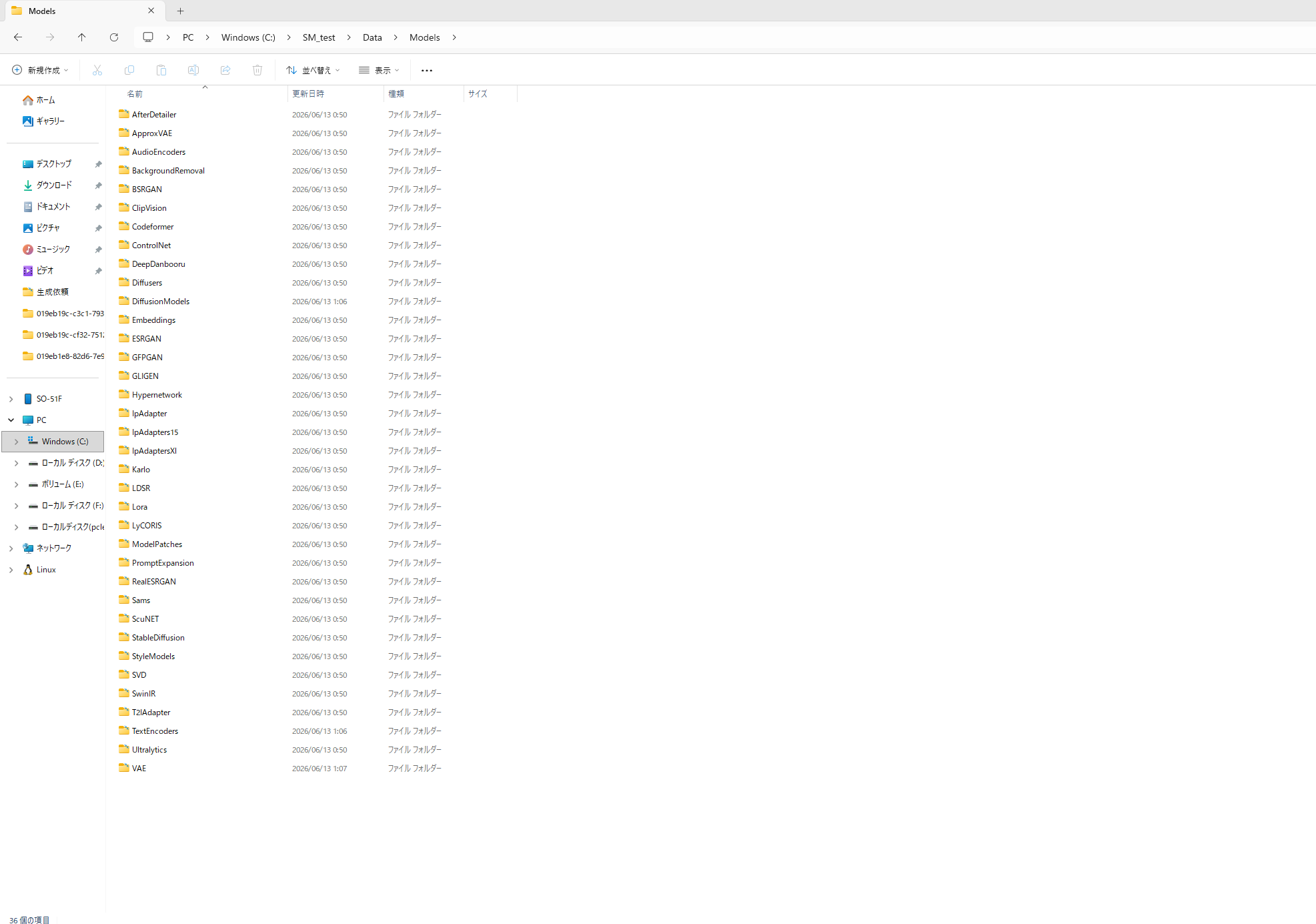
Stability Matrixの最大の魅力が、モデルの一元管理です。
データフォルダ内の「Models」に種類別のフォルダが自動で作られ、ここに置いたモデルはStability Matrix経由のUIから共有で使えます。
Animaは3つのファイルで動きます。それぞれ次の場所に置きます。
- DiffusionModels ← 本体「anima_baseV10.safetensors」(3.89GB)
- TextEncoders ← テキストエンコーダ「qwen_3_06b_base.safetensors」(1.11GB)
- VAE ←「qwen_image_vae.safetensors」(0.24GB)
最初の1枚を生成する
手順1. ComfyUIを起動
Stability Matrixのパッケージ画面から「Launch」。
コンソールにログが流れ、準備が終わるとブラウザでComfyUIが開きます。
手順2. テンプレートを読み込む
メニューから「テンプレートを参照」→検索欄に「anima」。
「Anima Base v1:テキストから画像へ」を読み込みます。
もう1つ「Anima アニメ文生図」も見つかりますが、本記事の画面と実測値はBase v1のものです。
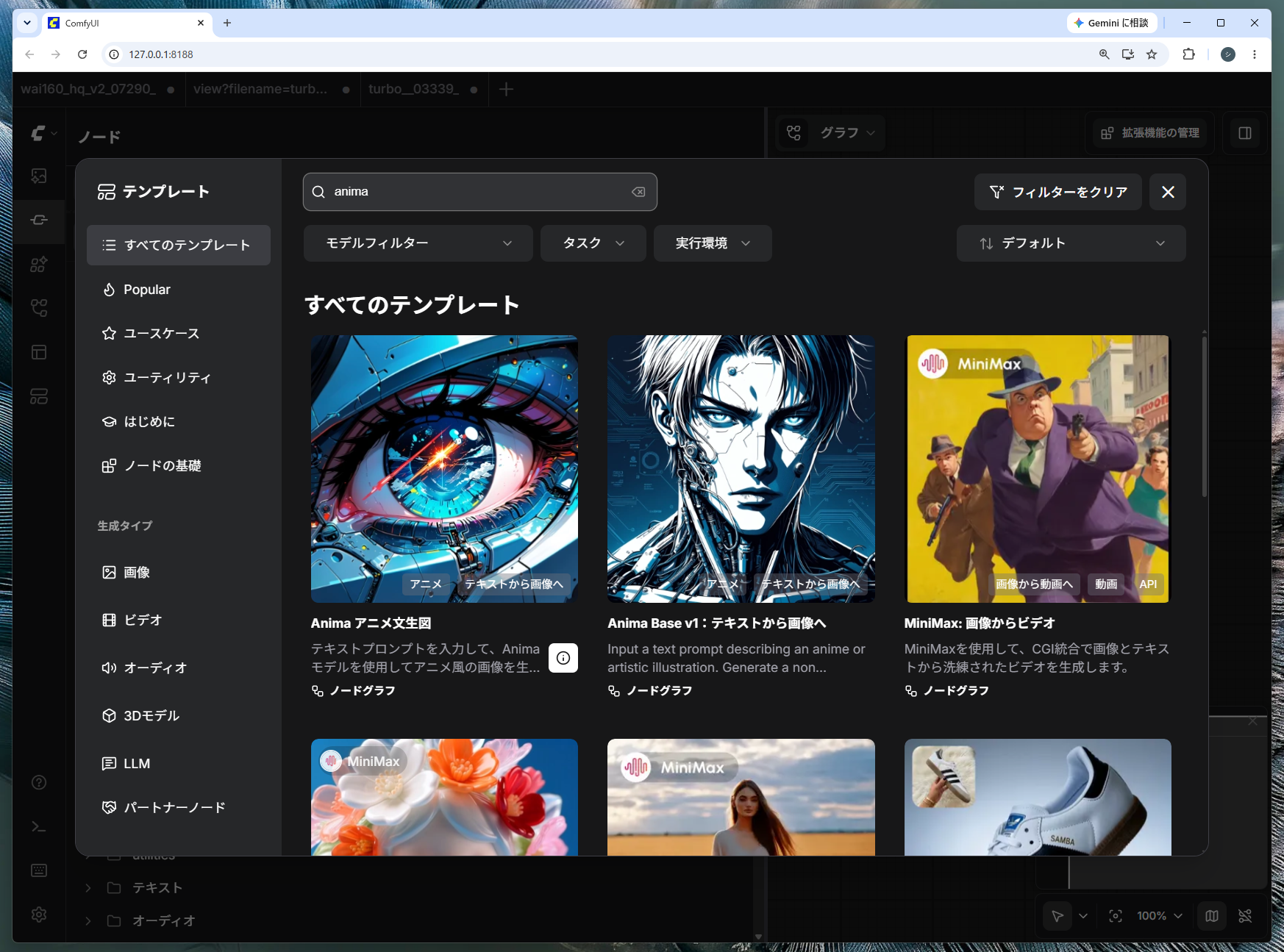
手順3. モデルを割り当てる
読み込んだワークフローのプルダウンで、3つのファイルを選びます。
- unet_name →「anima_baseV10.safetensors」
- clip_name →「qwen_3_06b_base.safetensors」(同じノード内にある「タイプ」欄は「qwen_image」を選択)
- vae_name →「qwen_image_vae.safetensors」
手順4. 実行
生成条件はテンプレート既定のまま「1024×1024 / 30ステップ / CFG 4.0」。
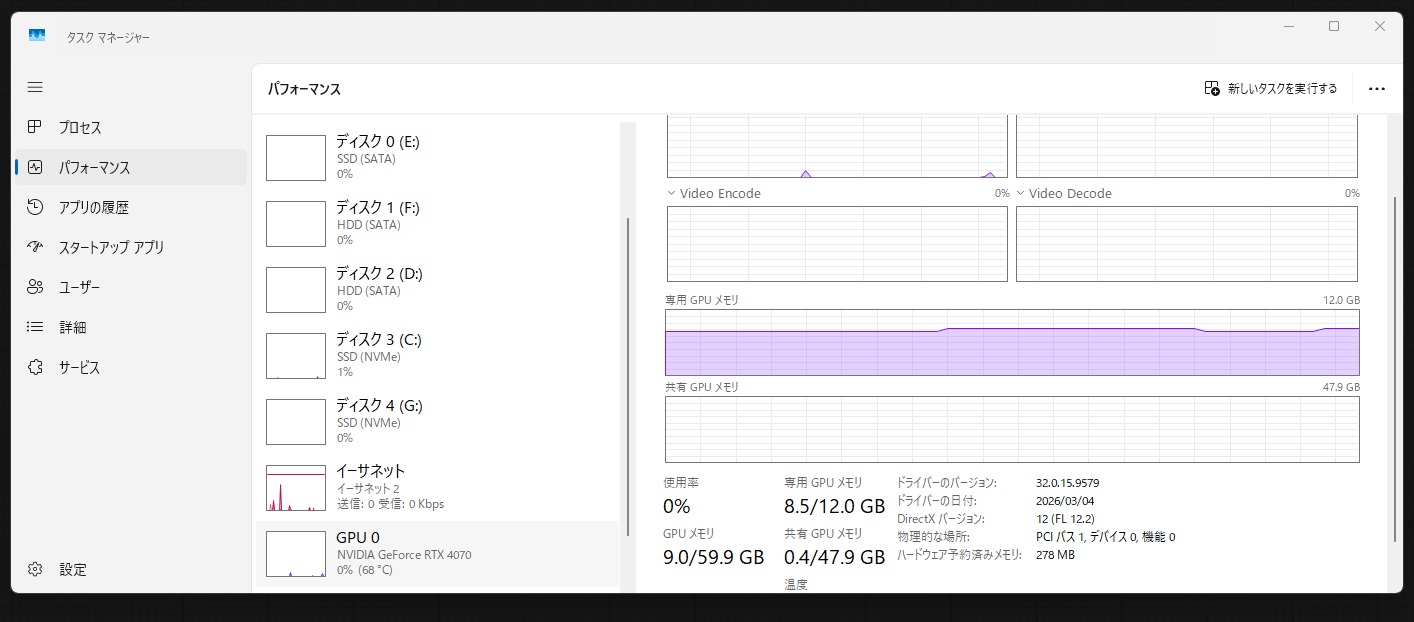
実測値は次のとおりでした。
| 項目 | 実測値 |
|---|---|
| 初回生成(モデル読み込み込み) | 40.13秒 |
| 2回目以降 | 22.73秒 |
| 生成中のVRAM使用 | 8.5GB前後 / 12GB |
| GPU使用率・温度 | 94%・71℃ |
気づいたこと
実際にゼロから入れ直して、気づいたことが1つありました。
テンプレートの案内と、実際のモデル名が違う——
ComfyUI公式テンプレートの説明書きは「anima-preview3」(プレビュー版)を案内しています。ですが、正式版の「anima_baseV10.safetensors」で問題なく動きました。
今回の環境では、これ以外のトラブルは起きませんでした。
まとめと次回予告
RTX 4070(12GB)で、ComfyUI+Animaは「1枚約23秒・VRAM 8.5GB」で動きました。
ディスクの空きは、15GBあれば足ります。
次回は、この環境でモデル別の生成速度とVRAM使用量を比較測定する予定です。実機の数字でお会いしましょう。
おまけ:Animaで生成した1枚
最後に、Animaで生成した1枚を載せておきます。
「帰り道、ふと振り返ってはにかむ女子高生」という指定で生成しました。こちらは筆者の普段の環境(この記事の構成にLoRAやプロンプト補助を足したもの)によるものです。
夕暮れの逆光、住宅街の電柱、こちらを向いた視線——指定した要素がきちんと入っています。

コメントを残す